Project portfolio of linguistic applications
APPLICATION DEVELOPMENT
Table of contents
Interactive map-based data exploration

-
Documents et analyses de la Galloromania médiévale (GallRom)

- Ancient Italo-Romance varieties through open-access linguistic maps (MIRA)
- A mapping tool designed to generate customizable map images (MapLing)
- Audio recordings and visual inputs associated to places in Switzerland (Stimmen der Schweiz)
-
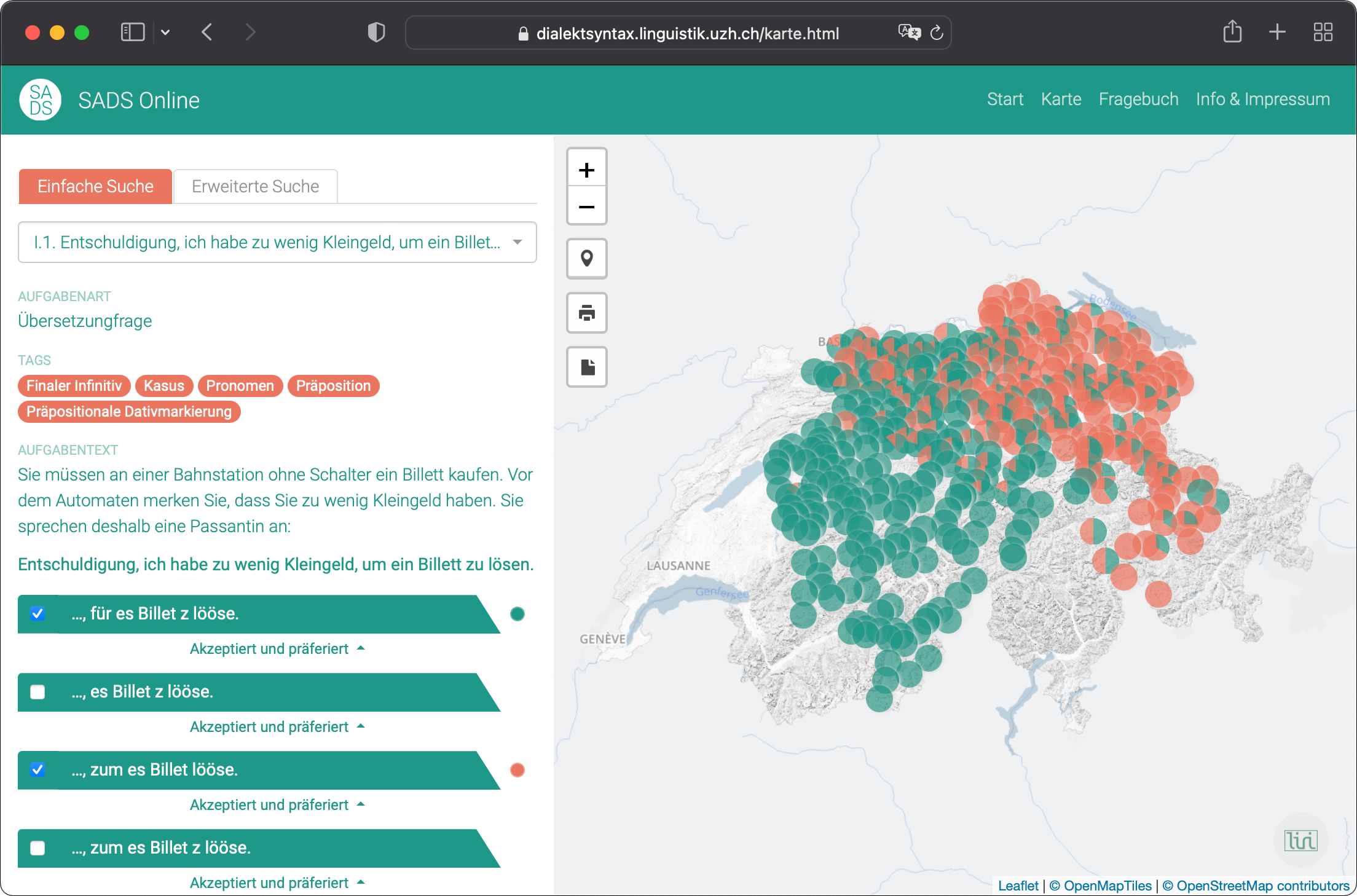
Questionnaire data regarding acceptability of syntactic variants in Switzerland (Syntaktischer Atlas der deutschen Schweiz)
-
Goal: development of a website which makes a collected data set (with metadata and the answers to 118 questions about morphosyntactic variables of Swiss German) available to interested public while keeping the possibility of advanced search of the database for researchers
-
-
In the scope of the both map-based data exploration projects the following tasks were performed:
-
Analysis and processing of anonymised data with geographical references
-
Development of an interactive user interface with different search and filter options
-
Development of a static map solution using a combination of OpenMapTiles, QGIS and Leaflet
-
Additionally, for the Syntaktischer Atlas der deutschen Schweiz project, different map representations were implemented (regular map, clusters, heatmap) together with a logical query language, which allows researchers to query the database individually
-
Management of research data
-
Expert system for annotation of historic corpora, management of bibliography data and lexicon curation in an interactive application (Lexique étymologique de la Galloromania médiévale (LEGaM))
-
Definition of abstract data structure: Through Q&A with customer, the data structures lying behind the project were elicidated and technically modeled and implemented.
-
Data exploration: Existing systems (databases, applications, data files) were analyzed, processed, and transformed into new defined, general structure.
-
User interface: A web-based user interface for managing the existing and adding new data was step-wise implemented, flanked by a flexible issue-tracking system, regularly customer consultations, and agreeing on well-defined milestones.
-
-
Exploration of annotated manuscripts (Répertoire critique des manuscrits littéraires en ancien occitan (RC))
-
Extending data model: The RC project was decided to be integrated into the LEGaM system - therefore, compatible adjustments to the already existing data structure had to be implemented.
-
User/Acces management:
-
-
Data-driven historical linguistics (Language variation in the Middle Ages as a system. New foundations for the scriptological description of medieval Gallo-Romance (Scripta))
Corpus tools
-
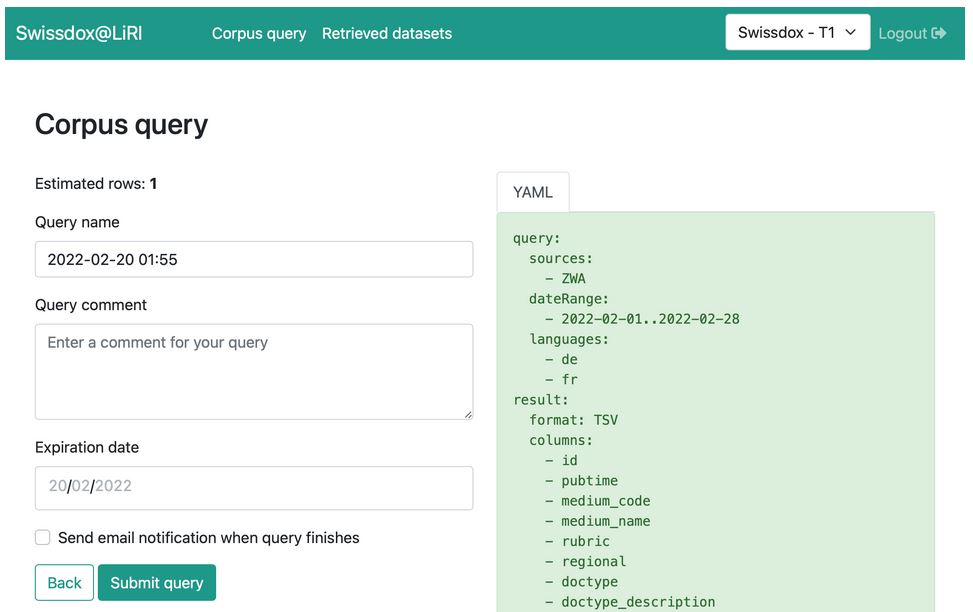
Extraction of subcorpora from the Swiss media database Swissdox
-
Goal: development of a user interface which will make Swissdox (online media database) data available for academic work
-
Optimization of the existing database structure for big data querying
-
Architecture design which supports big data queries - e.g. background processing and notification system when query is finished
-
Development of a user interface with built-in query builder for filtering and fetching large amounts of data
-
Import scripts for new media data that run on a daily basis
-
Monitoring of database and server performances
-
-
A platform for hosting and querying potentially large corpora with diverse structures (LiRI corpus platform)
-
Goal: deploy a web application that allows users to manipulate annotated linguistic corpora for quantitative or mixed-methods research
-
The application allows users to find instances and frequencies of arbitrarily complex lexicogrammatical phenomena
-
We aim to bring the power and functionality of existing command-line applications to a graphical web environment
-
Performant and stable handling of documents containing billions of words and numerous layers of annotation
-
Users should be able to create and manage complex queries
-
Queries can be transformed into frequency tables and charts, or exported as raw data for processing by other applications
-
An API will allow programmatic access to the main functionality of the platform
-
NLP tools
-
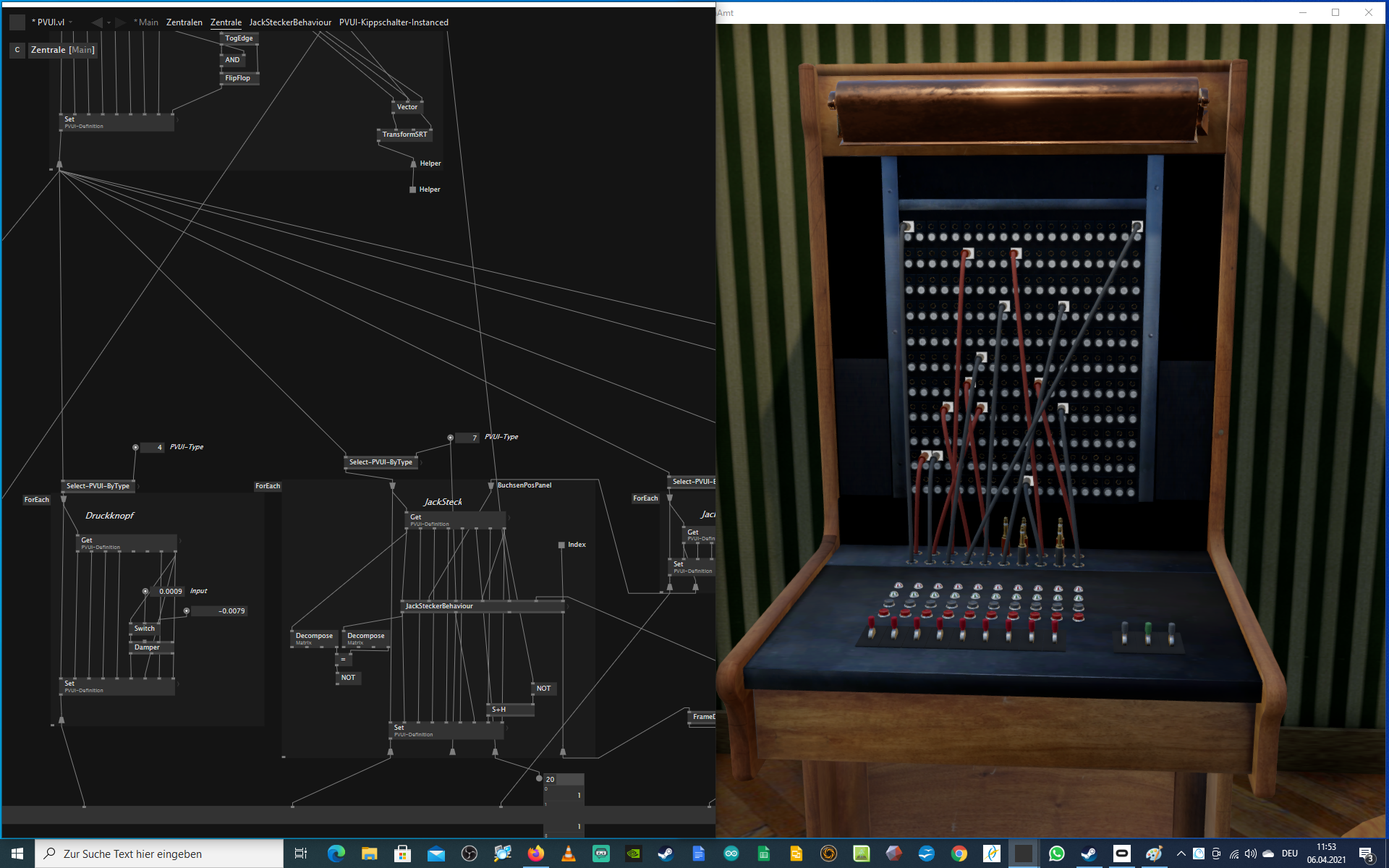
Speech-to-text backend for virtual telephone switchboard (Virtuelle Telefonzentrale)
-
Implementation of a virtual telephone switchboard in which players can assume the role of a switchboard operator.
-
Goal: to make a historic communication situation tangible and to try out VR as a research method.
-
In the context of the project, LiRI implemented the component for automatic speech recognition to identify the utterances of the switchboard operator.
-